A first step towards R from spreadsheets
Move your data analysis to a computing environment specifically designed for it.
Why R and not spreadsheets?
Here are three reasons:
- complexity
- graphics
- money
Spreadsheets are easily overwhelmed. Very complex things can be done in spreadsheets — it is just that complex spreadsheets are inefficient and dangerous.
Graphics should be considered vital when doing anything with data. R has amazing graphical capabilities.
It is becoming more and more common for advertisements for jobs involving data analysis to mention R. The demand for people who know R is growing rapidly. The jobs that mention R are better paid than those that just require spreadsheets. And rightly so — data analysis is done better and faster in R.
If you are an employer, you will get more data analysis for the amount you spend by moving to R (plus the analyses are more likely to be bug-free). If you do data analysis, then you may be able to get higher pay by knowing R — maybe not now but probably soon.
Get to the starting gate
Obviously you need to install R on your computer before you can use it. That’s easy to do — you’re unlikely to have any problems.
You can use R as you’ve just downloaded it, but a nicer way is via RStudio, which also appears to have non-problematic installation. I believe that if you install RStudio without installing R first, then it will do the R installation as well.
Read in some data
If you have files of data in either comma separated or tab separated format, then it is (usually) easy to read those files into R:
Here’s the comma separated example:
superbowl <- read.table( "http://www.portfolioprobe.com/R/blog/dowjones_super.csv", sep=",", header=TRUE)
The command above reads the data from the file and puts it into an object called superbowl.
You can create a plot with this data:
plot(DowJonesSimpleReturn ~ Winner, data=superbowl)
That command makes a rather austere plot. You can make it prettier with some minor additions as in Figure 1:
plot(100 * DowJonesSimpleReturn ~ Winner, data=superbowl, col="powderblue", ylab="Return (%)")
Figure 1: Boxplot of Super Bowl data. 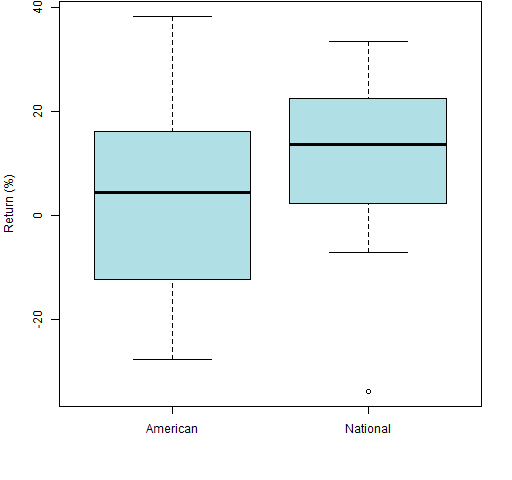
If you don’t understand them, you should read an explanation of boxplots. You can also learn about the somewhat horrifying story of the Super Bowl data.
Data frames are familiar
The superbowl object that was created above is a data frame. Data frames are R objects that are very much like the most common way of using spreadsheets:
- the data are rectangular
- columns hold variables
- rows hold observations
In both spreadsheets and R there are likely to be different types of data in different columns: numbers, character data, dates and so on. The difference is that R forces there to be only one type of data in a column.
You can look at the first few rows:
> head(superbowl)
Winner DowJonesSimpleReturn DowJonesUpDown DowJonesCorrect
1967 National 0.15199379 Up correct
1968 National 0.04269094 Up correct
1969 American -0.15193642 Down correct
1970 American 0.04817832 Up wrong
1971 American 0.06112621 Up wrong
1972 National 0.14583240 Up correct
The “> ” is R’s prompt, you type what is after it (and hit the “return” or “enter” key).
You can also see how big it is:
> dim(superbowl) [1] 45 4
This says that there are 45 rows and 4 columns. You might have expected the number of columns to be 5 and not 4. The years on the very left are row names rather than actually part of the data, similar to how “Winner” is a column name and not part of the data proper.
A slice of computing
R includes a number of datasets that are automatically attached. One of them is airquality:
> tail(airquality)
Ozone Solar.R Wind Temp Month Day
148 14 20 16.6 63 9 25
149 30 193 6.9 70 9 26
150 NA 145 13.2 77 9 27
151 14 191 14.3 75 9 28
152 18 131 8.0 76 9 29
153 20 223 11.5 68 9 30
You can ask for help on this object:
?airquality
This is the same way you ask for help for functions.
The temperature is in Fahrenheit. You can create a new object that is temperature in Celsius:
Ct <- with(airquality, (Temp - 32) / 1.8)
The last few values in this object are:
> tail(Ct) [1] 17.22222 21.11111 25.00000 23.88889 24.44444 [6] 20.00000
The Ct object is a vector, not a data frame.
Alternatively, you can make a new data frame with an additional column containing the temperature in Celsius:
newAir <- within(airquality, Ctemp <- (Temp - 32) / 1.8)
Of course, you can look at the first few rows of the new object:
> head(newair) Error in head(newair) : object 'newair' not found
This wrong command shows that:
- R is case-sensitive:
newAiris different fromnewair - the world doesn’t end if you make a mistake
The proper command is:
> head(newAir) Ozone Solar.R Wind Temp Month Day Ctemp 1 41 190 7.4 67 5 1 19.44444 2 36 118 8.0 72 5 2 22.22222 3 12 149 12.6 74 5 3 23.33333 4 18 313 11.5 62 5 4 16.66667 5 NA NA 14.3 56 5 5 13.33333 6 28 NA 14.9 66 5 6 18.88889
Some R resources
“Impatient R” provides a grounding in how to use R.
“Some hints for the R beginner” suggests additional ways to learn R.
R For Dummies is one possible book to use to learn R. In particular, it has a chapter called: “Ten Things You Can Do in R That You Would’ve Done in Microsoft Excel”. Those things include:
- Adding row and column totals
- Formatting numbers
- Finding unique or duplicated values
- Working with lookup tables
- Working with pivot tables
- Using the goal seek and solver
Additional blog posts
- From spreadsheet thinking to R thinking (includes a table of a large number of spreadsheet functions and the equivalent in R)



If you’re using Postgres for RDBMS, then you can embed R in your application using PL/R. And, while I’ve not attempted, PG/9.3 has improved foreign databases (aka, federation) integration, so one could use R functions in the PG engine and report (and write, to some extent) from other databases. There is, at yet, no native driver for DB2 (JDBC/ODBC will work), but there are for most other databases.
and yet…the example provided could easily be done in excel
and the R output has, at least in the graph shown, the same hideous lookng default formatting as excel
so…
show me a REAL example of why R is better then excel
(a good one would be x,y data, x irregular time intervals, y some variable ; you do a linear regression in excel, fine, no problme, but what happens when you want lines showing the 95% ci for the regression line
possible, but hard
or smoothly fit a 4,5 paramter logistic fit to a sigmoid curve and extract min, max, slope, midpoint with CI…
Great stuff Pat, nice to see R being extolled for spreadsheeters. First thing I do with any spreadsheet-loving students is send them to read your Spreadsheet Addiction. But they still get scared by the code. What do you think of the new R Commander version? I’m pretty impressed, as an entry-level for beginners.
Robert,
Thanks — I haven’t looked at R Commander in a while. I think anything that reduces the fear and trouble of converting to R is a good thing.
Pretty nice article. I will keep that in mind for a later use.
Your introduction concerning more salary due to R experience, reminded me of a paper i recently read. It has even brought first evidence, about the relation of early investments of experts with data science skills and firm productivity: http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2294077
Teaser from the abstract: “The estimates indicate that from 2006 to 2011, firms’ use of big data technologies, measured as the employment of engineers with Hadoop skills, was associated with 3% faster productivity growth, but only for firms with a) significant data assets and b) access to technical workers from other early big data adopters.”
In a blog post called “Why use R?” Josh Ulrich points out that the thought process is explicit in R code but not in spreadsheets.
Another blog post on switching to R from Excel (from a totally different point of view) is “R you still using Excel?”
Trackbacks & Pingbacks
[…] https://www.burns-stat.com/first-step-towards-r-spreadsheets/ […]
[…] If you analyse data and particularly statistics, you should really have R in your toolbox. Like all programming, it makes light work of repetitive tasks. As a trade off, there’s a learning curve involved. Thankfully the syntax is easy to get to grips with (if I can manage it, anyone can). There are some tips here for moving from spreadsheets to R. […]
[…] https://www.burns-stat.com/first-step-towards-r-spreadsheets/ […]
[…] https://www.burns-stat.com/first-step-towards-r-spreadsheets/ […]
[…] R and not spreadsheets?” https://www.burns-stat.com/first-step-towards-r-spreadsheets/… via […]
Leave a Reply
Want to join the discussion?Feel free to contribute!